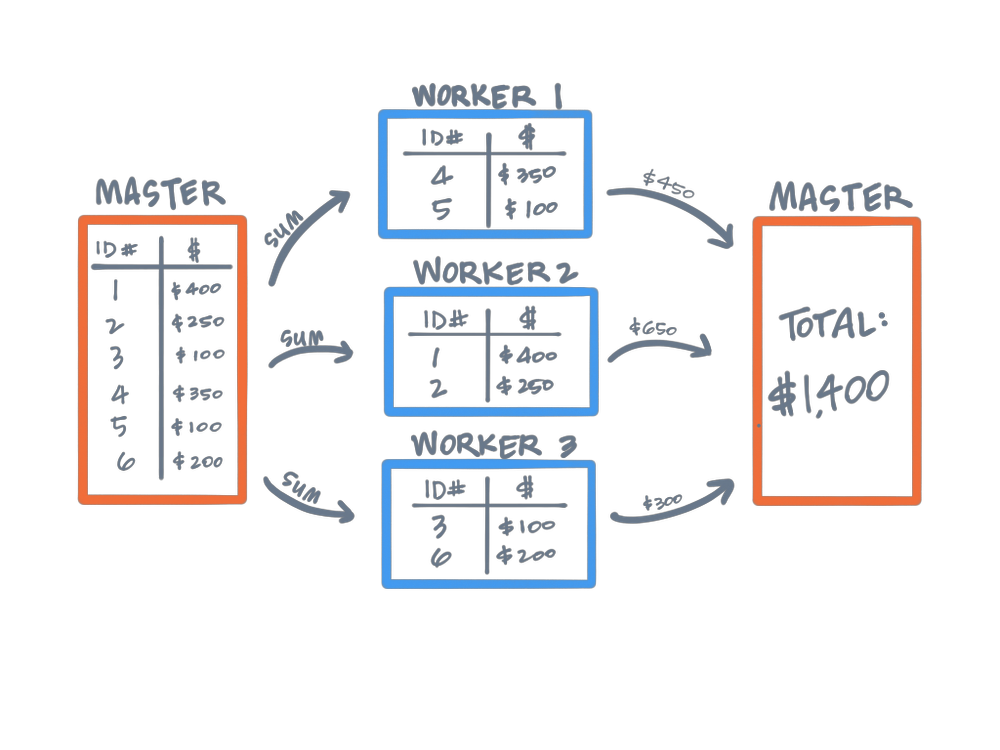
Map Partitions In Spark . pyspark provides two key functions, map and mappartitions, for performing data transformation on. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. map() and mappartitions() are two transformation operations in pyspark that are used to process and transform data in a distributed manner. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. Map() is a transformation operation that applies a. mappartition should be thought of as a map operation over partitions and not over the elements of the partition. spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the new.
from www.jowanza.com
learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. Map() is a transformation operation that applies a. map() and mappartitions() are two transformation operations in pyspark that are used to process and transform data in a distributed manner. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. pyspark provides two key functions, map and mappartitions, for performing data transformation on. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark. mappartition should be thought of as a map operation over partitions and not over the elements of the partition. spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the new.
Partitions in Apache Spark — Jowanza Joseph
Map Partitions In Spark spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the new. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. pyspark provides two key functions, map and mappartitions, for performing data transformation on. map() and mappartitions() are two transformation operations in pyspark that are used to process and transform data in a distributed manner. Map() is a transformation operation that applies a. spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the new. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. mappartition should be thought of as a map operation over partitions and not over the elements of the partition. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark.
From github.com
sparkdl.xgboost getting stuck trying to map partitions · Issue 248 Map Partitions In Spark learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the new. mappartition should be thought of as a map operation over partitions and not over the elements of the partition. map(). Map Partitions In Spark.
From www.educba.com
PySpark mappartitions Learn the Internal Working and the Advantages Map Partitions In Spark mappartition should be thought of as a map operation over partitions and not over the elements of the partition. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. pyspark provides two key functions, map. Map Partitions In Spark.
From sparkbyexamples.com
Spark map() vs flatMap() with Examples Spark By {Examples} Map Partitions In Spark learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. pyspark provides two key functions, map and mappartitions, for performing data transformation on. spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the new. the mappartitions() function applies the provided function. Map Partitions In Spark.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Map Partitions In Spark the mappartitions() function applies the provided function to each partition of the dataframe or rdd. map() and mappartitions() are two transformation operations in pyspark that are used to process and transform data in a distributed manner. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark. learn. Map Partitions In Spark.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Map Partitions In Spark mappartition should be thought of as a map operation over partitions and not over the elements of the partition. map() and mappartitions() are two transformation operations in pyspark that are used to process and transform data in a distributed manner. Map() is a transformation operation that applies a. the mappartitions() function applies the provided function to each. Map Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Map Partitions In Spark pyspark provides two key functions, map and mappartitions, for performing data transformation on. mappartition should be thought of as a map operation over partitions and not over the elements of the partition. Map() is a transformation operation that applies a. map() and mappartitions() are two transformation operations in pyspark that are used to process and transform data. Map Partitions In Spark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Map Partitions In Spark mappartition should be thought of as a map operation over partitions and not over the elements of the partition. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. Map() is a transformation operation that applies. Map Partitions In Spark.
From www.xpand-it.com
meetupsparkmappartitions Xpand IT Map Partitions In Spark Map() is a transformation operation that applies a. pyspark provides two key functions, map and mappartitions, for performing data transformation on. mappartition should be thought of as a map operation over partitions and not over the elements of the partition. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. learn. Map Partitions In Spark.
From manushgupta.github.io
SPARK vs Hadoop MapReduce Manush Gupta Map Partitions In Spark mappartition should be thought of as a map operation over partitions and not over the elements of the partition. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. Map() is a transformation operation that applies. Map Partitions In Spark.
From stackoverflow.com
partitioning How can be exploited Parquet partitions loading RDD in Map Partitions In Spark mappartition should be thought of as a map operation over partitions and not over the elements of the partition. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. Map() is a transformation operation that applies. Map Partitions In Spark.
From medium.com
Spark Under The Hood Partition. Spark is a distributed computing Map Partitions In Spark mappartition should be thought of as a map operation over partitions and not over the elements of the partition. Map() is a transformation operation that applies a. pyspark provides two key functions, map and mappartitions, for performing data transformation on. spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and. Map Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Map Partitions In Spark the mappartitions() function applies the provided function to each partition of the dataframe or rdd. pyspark provides two key functions, map and mappartitions, for performing data transformation on. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. map() and mappartitions() are two transformation operations in pyspark that are used. Map Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Map Partitions In Spark mappartition should be thought of as a map operation over partitions and not over the elements of the partition. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark. spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the. Map Partitions In Spark.
From proedu.co
Apache Spark RDD mapPartitions and mapPartitionsWithIndex Proedu Map Partitions In Spark learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. mappartition should be thought of as. Map Partitions In Spark.
From gmucciolo.it
Spark and Hadoop Developer Gianluigi Mucciolo Map Partitions In Spark pyspark provides two key functions, map and mappartitions, for performing data transformation on. mappartition should be thought of as a map operation over partitions and not over the elements of the partition. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. Map() is a transformation operation that applies a. map(). Map Partitions In Spark.
From sparkbyexamples.com
Spark How to Convert Map into Multiple Columns Spark By {Examples} Map Partitions In Spark spark map () and mappartitions () transformations apply the function on each element/record/row of the dataframe/dataset and returns the new. Map() is a transformation operation that applies a. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. the mappartitions() function applies the provided function to each partition of the dataframe. Map Partitions In Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Map Partitions In Spark pyspark provides two key functions, map and mappartitions, for performing data transformation on. learn how 'mappartitions' is a powerful transformation that allows spark programmers to process partitions as a. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark. Map() is a transformation operation that applies a. . Map Partitions In Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Map Partitions In Spark Map() is a transformation operation that applies a. pyspark provides two key functions, map and mappartitions, for performing data transformation on. learn how to use the mappartitions function to apply a function to each partition of an rdd in pyspark. the mappartitions() function applies the provided function to each partition of the dataframe or rdd. map(). Map Partitions In Spark.